Analysis
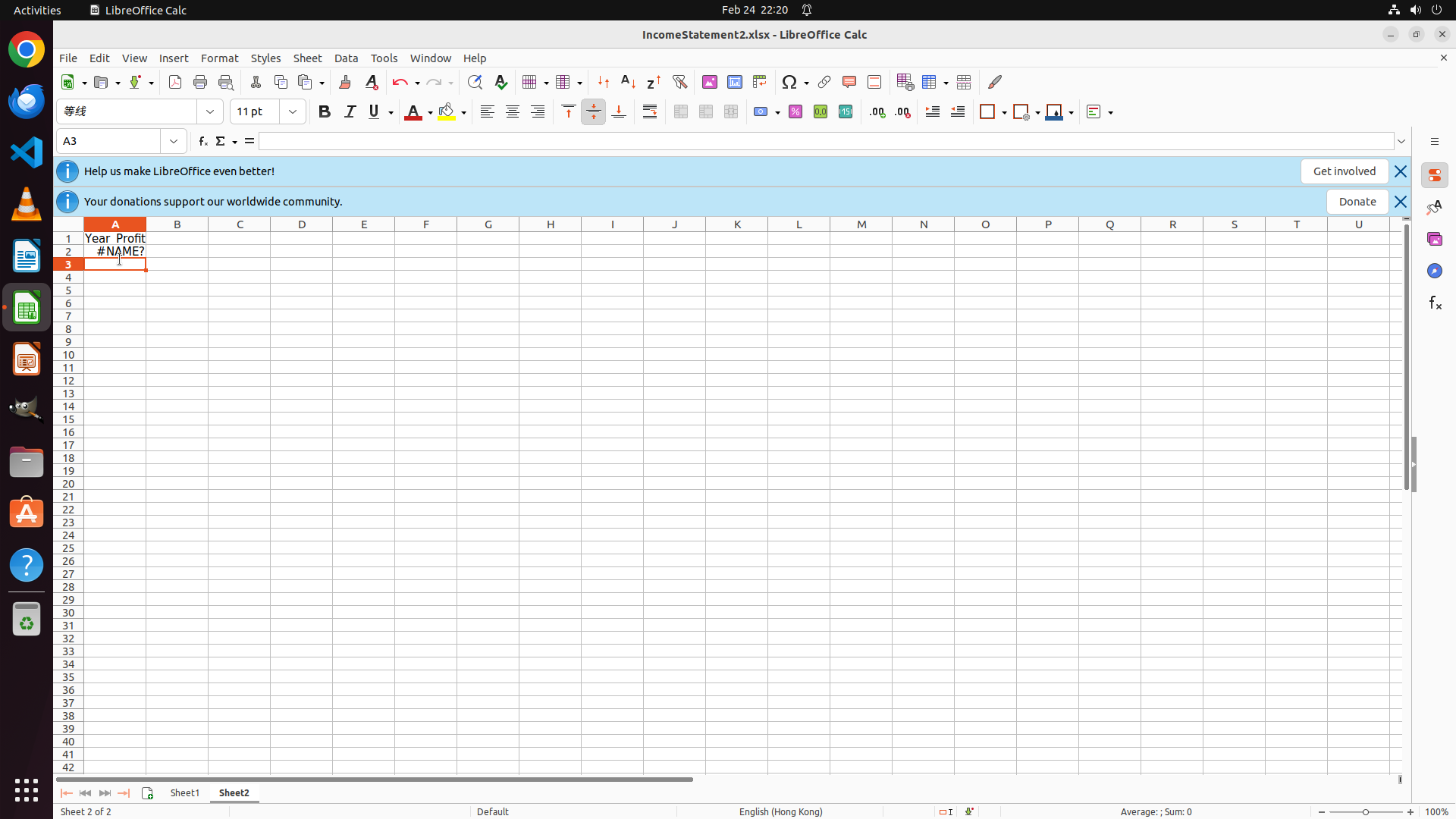
Data Generation Pipeline Ablation
We ablate the key design choices of LearnWeak-Gen: iterative generation and weakness-report conditioning.
Domain
Specialization |
Iterative
Generation |
Weakness
Report |
Calc |
Impress |
VLC |
VSCode |
Avg. |
| ✗ | ✗ | ✗ |
28.07 | 37.66 | 45.71 | 51.30 |
40.69 |
| ✓ | ✗ | ✗ |
34.57 | 39.72 | 47.06 | 73.91 |
48.82 |
| ✓ | ✓ | ✗ |
24.82 | 42.55 | 43.14 | 72.46 |
45.74 |
| ✓ | ✓ | ✓ |
41.13 | 50.35 | 56.86 | 72.46 |
55.20 |
One-shot (no iteration, no weakness report)
Iterative, no weakness report
Full pipeline (LearnWeak)
Key Insight: Iteration alone is insufficient; weakness-aware guidance is essential
One-shot domain specialization (no iteration) already provides a useful baseline (40.69 → 48.82 avg.).
However, adding iteration without the weakness report actually hurts performance (45.74 avg.), showing that exploration-only generation fails to collect effectively targeted training samples.
The full pipeline combining iteration with weakness-report conditioning achieves the best result (55.20 avg.), demonstrating that the benefit of iterative expansion depends on student-aware guidance.
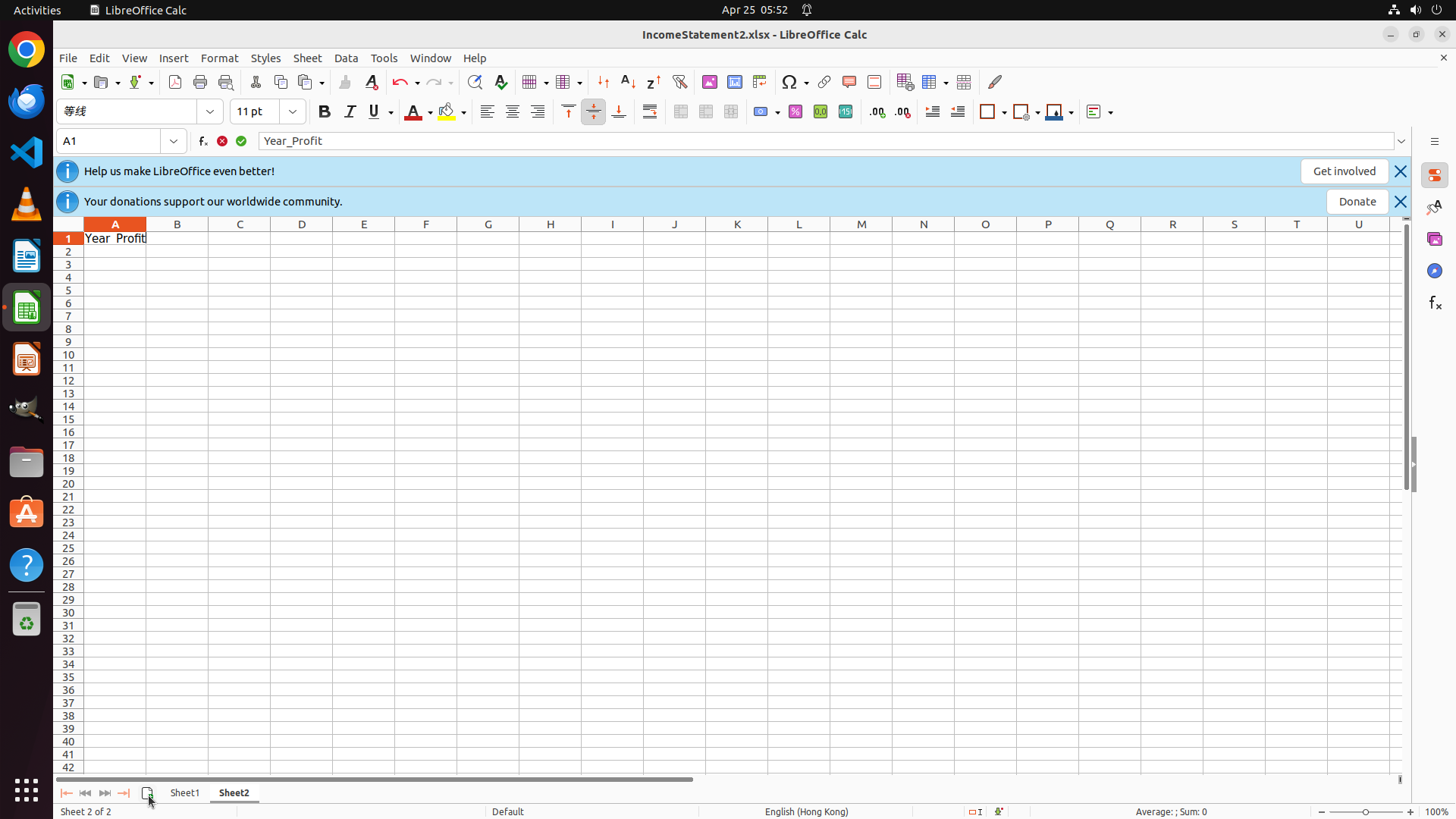
Effect of Teacher Choice
| Teacher Policy |
Teacher |
Specialized Student |
| Calc | VSCode |
Calc | VSCode |
| Zero-shot |
— | — |
28.07 | 51.30 |
| Claude Haiku 4.6 |
36.17 | 69.60 |
30.50 | 71.01 |
| EvoCUA-32B |
51.06 | 65.22 |
41.13 | 72.46 |
| Kimi K2.5 |
63.83 | 86.96 |
41.13 | 73.91 |
Teacher strength matters up to a point: the weaker Claude Haiku 4.6 yields smaller student gains than EvoCUA-32B or Kimi K2.5. Yet despite a large gap in their own success rates, EvoCUA-32B and Kimi K2.5 produce nearly identical specialized student performance. Once the teacher is strong enough to generate reliable trajectories, further gains depend on whether its supervision targets actionable weaknesses for the student, not on raw teacher performance.
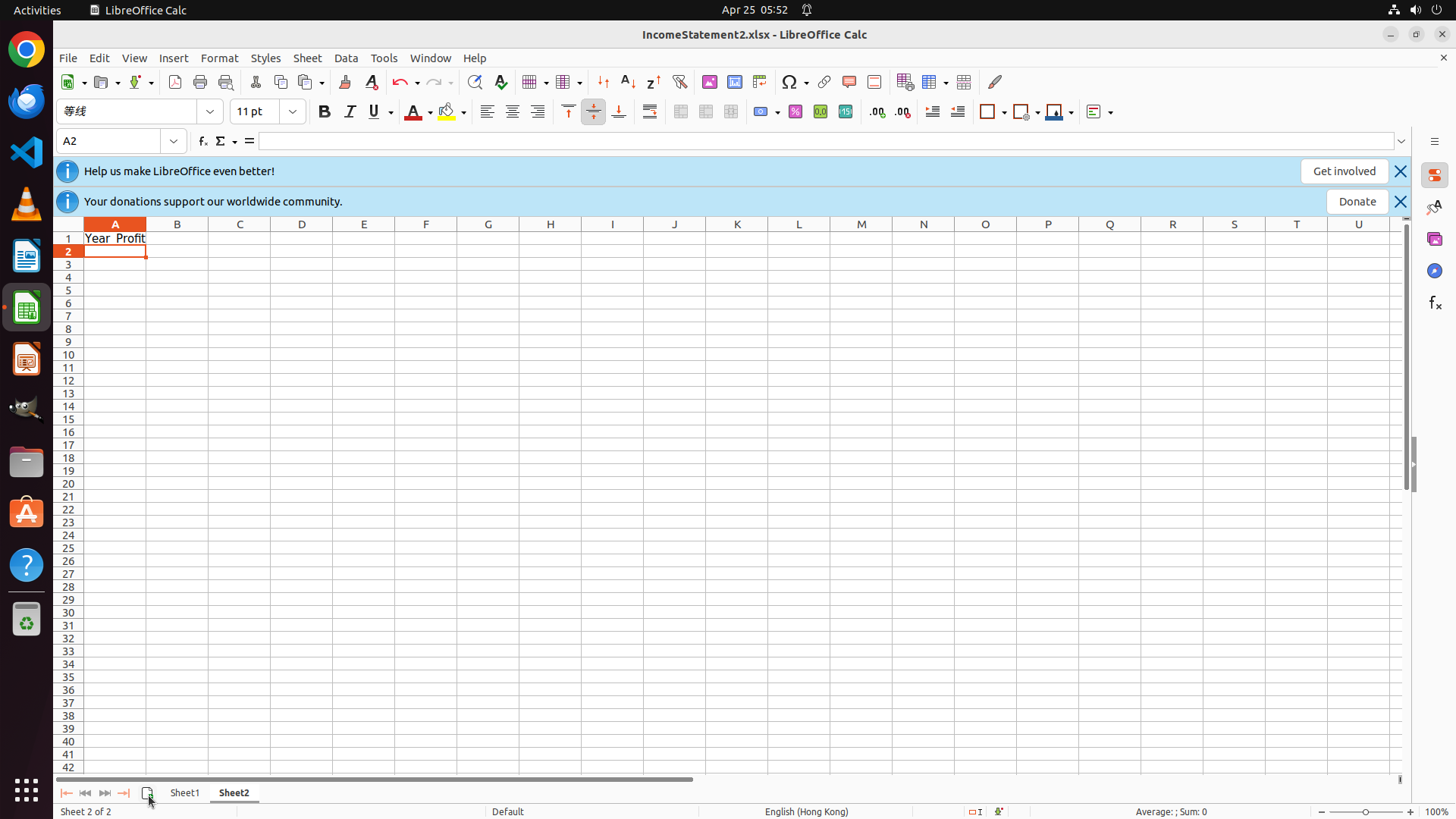
Student-Awareness of Dataset Generation
We train each target model on datasets constructed from weakness reports derived from different source students. Because failure cases and weakness types differ across student models, a student-aware generator produces the most useful data when the weakness report is derived from the target model itself.
| Target Model $\pi_\theta$ / Source Student $\pi_S$ |
Calc |
Impress |
VLC |
VSCode |
| Zero-shot |
11.91 | 31.49 | 32.94 | 51.30 |
| Source: EvoCUA-8B |
9.93 | 27.54 | 45.10 | 50.72 |
| Source: UI-TARS-1.5-7B |
7.80 | 33.35 | — | 49.28 |
| Source: OpenCUA-7B (own) |
19.15 | 36.88 | 47.06 | 62.32 |
| Zero-shot |
28.07 | 37.66 | 45.71 | 51.30 |
| Source: UI-TARS-1.5-7B |
22.70 | 31.21 | — | 71.01 |
| Source: OpenCUA-7B |
39.01 | 43.26 | 47.06 | 73.91 |
| Source: EvoCUA-8B (own) |
41.13 | 50.35 | 56.86 | 72.46 |
Both models achieve the highest performance when trained on datasets generated from their own failure cases, while cross-student datasets yield consistently lower gains.
This confirms that LearnWeak-Gen captures model-specific deficiencies rather than generic task distributions.
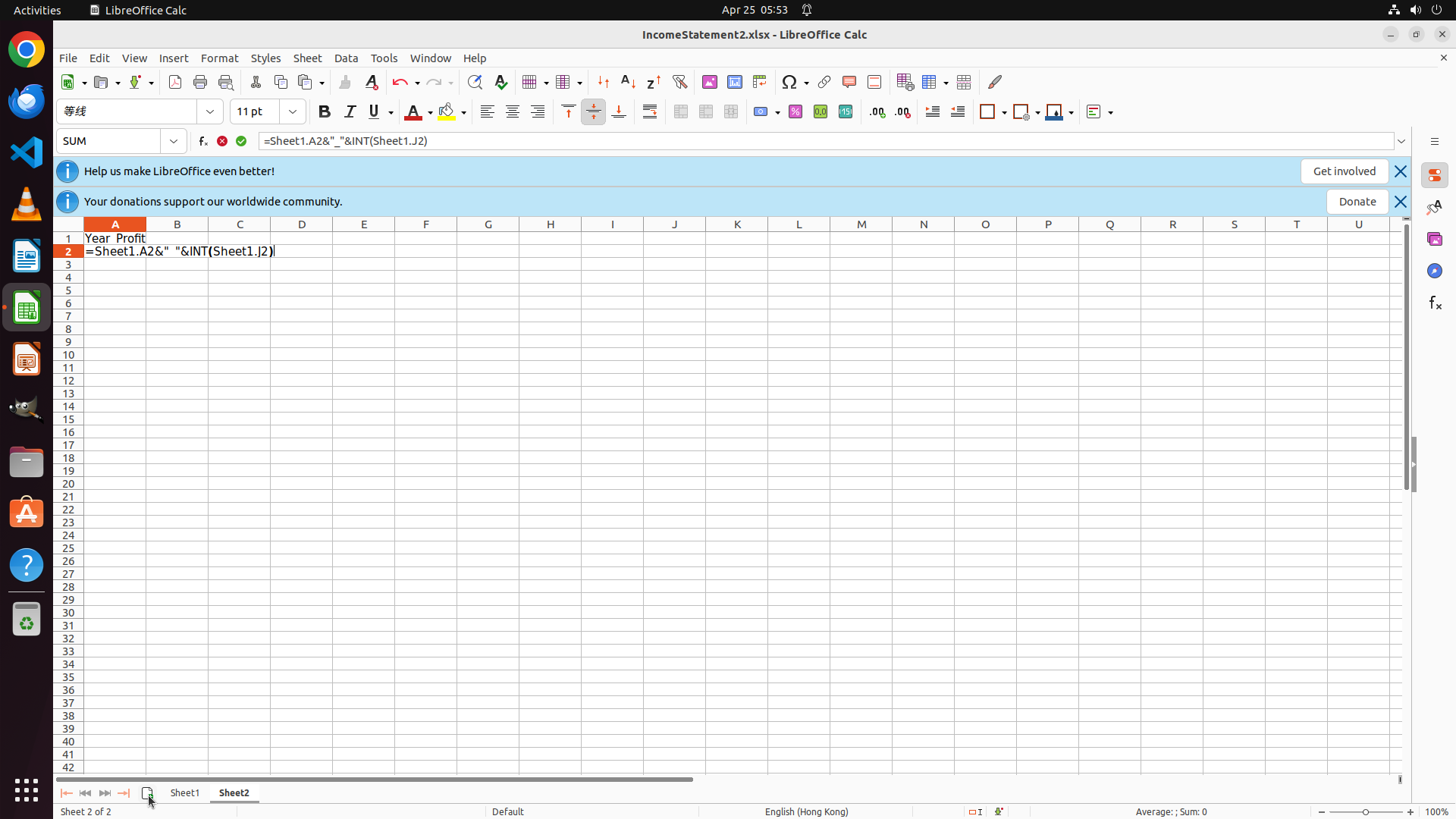
Training Objective Ablation
We compare LearnWeak-DPO with standard SFT, DPO, and variants with different error-aware supervision masks, all trained on the same dataset from LearnWeak-Gen.
| Method |
Calc |
Impress |
VLC |
VSCode |
Avg. |
| Zero-shot |
28.07 | 37.66 | 45.71 | 51.30 |
40.69 |
| Standard SFT ($m = \varnothing$) |
29.08 | 39.72 | 45.10 | 68.12 |
45.51 |
| LearnWeak-SFT |
34.04 | 46.81 | 45.10 | 69.57 |
48.88 |
| Standard DPO ($m = \varnothing$) |
27.66 | 40.43 | 49.02 | 65.22 |
45.58 |
| DPO, planning-only mask |
18.44 | 17.02 | 41.18 | 63.77 |
35.10 |
| DPO, execution-only mask |
24.82 | 39.72 | 45.10 | 71.01 |
45.16 |
| LearnWeak-DPO (Ours) |
41.13 | 50.35 | 56.86 | 72.46 |
55.20 |
Full-response optimization (standard SFT/DPO) improves only modestly. Error-aware masking consistently improves SFT, and LearnWeak-DPO outperforms standard DPO by 9.62 points on average.
Using only planning-level or only execution-level supervision is insufficient; effective specialization requires both.